Question 1
a. “Using database can overcome the drawbacks of file system to store data”- justify you opinion.07
Ans: Transitioning from a file system to a Database Management System (DBMS) is essential because file systems lack the mechanisms to ensure data reliability and safety. DBMS justifies its use by solving the following critical problems:
-
Ensuring Atomicity of Updates File systems cannot guarantee that complex updates happen correctly. If a system crashes during a fund transfer, data might be left in a broken state (e.g., money deducted but not credited). A DBMS guarantees atomicity, meaning a transaction is treated as a single unit, it either completes fully or not at all, preventing data corruption.
-
Handling Concurrent Access In file systems, if multiple users try to update data simultaneously, they can overwrite each other’s work (e.g., two people withdrawing money at the exact same moment). DBMSs use concurrency control mechanisms to manage simultaneous access, ensuring data remains accurate even with many users.
-
Reducing Redundancy and Inconsistency File systems encourage duplicating data across different files. This leads to redundancy and eventually inconsistency (e.g., a student’s address is updated in one file but not another). A DBMS centralizes data storage, ensuring that any update is instantly reflected across the entire system.
-
Enforcing Integrity and Security File systems bury data rules (like “balance > 0”) inside program code, making them hard to change. A DBMS enforces these integrity constraints globally. Additionally, while file systems often give “all-or-nothing” access, a DBMS provides granular security, allowing specific users to access only the data they need.
Conclusion
While file systems are sufficient for simple storage, they fail in multi-user environments. A DBMS is necessary to provide the consistency, security, and reliability required for modern applications.
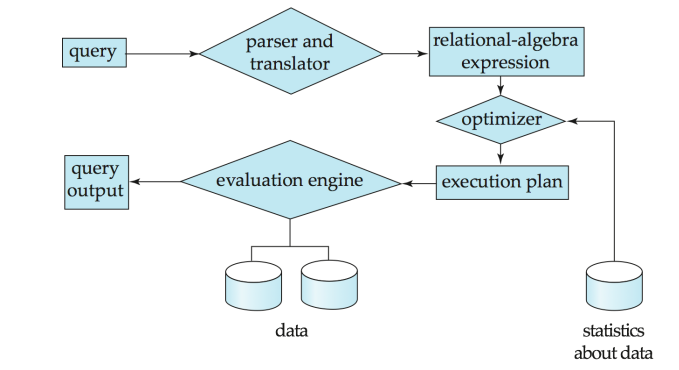
b. Summarize the procedure of Query Processing with pictorial representation.07
Ans:
- Parsing and translation
- Optimization
- Evaluation
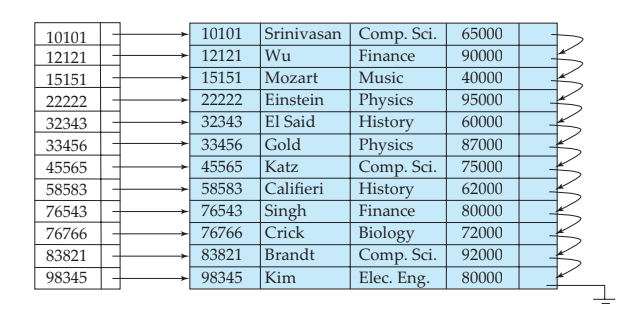
c. Outline the comparative view between sparse and dense indexing with appropriate examples. 06
Ans: There are two types of ordered indices that we can use:
- Dense index
In a dense index, an index entry appears for every search-key value in the file. In a dense non-clustering index, the index must store a list of pointers to all records with the same search-key value.
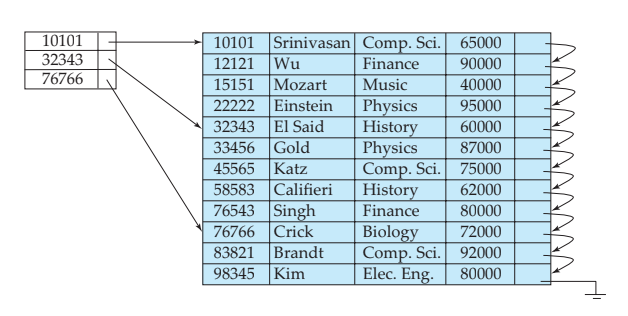
- Sparse index
In a sparse index, an index entry appears for only some of the search-key values. Sparse indices can be used only if the relation is stored in sorted order of the search key, that is, if the index is a clustering index.
Question 2
a. Consider the following relational schema for a restaurant database:13
Write a query in SQL for each of the following:
Ans:
- Find the name of restaurants who serves any type of ‘soup’ mentioned in the menu. 03
SELECT res_name
FROM restaurant
NATURAL JOIN menu
WHERE item_name LIKE '%soup%'; - Display the total number of orders placed, along with the total revenue generated by each restaurant.03
SELECT res_name, COUNT(order_id), SUM(total)
FROM resturant
NATURAL JOIN `order`
GROUP BY res_name;- Create a view named avg_price that displays the average price of menu items for each restaurant.03
CREATE VIEW avg_price AS
SELECT res_name, AVG(price)
FROM restaurant
NATURAL JOIN menu
GROUP BY res_name;- Display the names of customers who ordered “chicken_curry” from “Indian” restaurants, along with the order date and total amount spent.04
SELECT
C.cust_name,
O.date,
O.total
FROM
customer C
JOIN
"order" O ON C.cust_id = O.cust_id
JOIN
resturant R ON O.res_id = R.res_id
JOIN
menu M ON O.menu_id = M.menu_id
WHERE
M.item_name = 'chicken_curry'
AND R.res_type = 'Indian';b. Imagine, you are tasked to control the access of users (students, teachers, chairman) to a relation containing the marks of this course according to the authorization as:
| User | Class Test | Assignment | Final Exam |
|---|---|---|---|
| Student | View | View | No access |
| Teacher | Update/Insert | Update/Insert | Insert |
| Chairman | View | View | View |
Provide a conceptual idea to implement the authorization in terms of privileges in SQL. 07
Ans: To implement this securely and efficiently, we should not assign permissions to individual users directly. Instead, we create Roles (Student, Teacher, Chairman), assign specific privileges to these roles, and then add actual users to these roles.
We assume the relation is a table named CourseMarks with columns: student_id, class_test, assignment, and final_exam.
- Student
CREATE ROLE Student; GRANT SELECT (student_id, class_test, assignment) ON CourseMarks TO Student; - Teacher
CREATE ROLE Teacher; GRANT INSERT (class_test, assignment, final_exam) ON CourseMarks TO Teacher; GRANT UPDATE (class_test, assignment) ON CourseMarks TO Teacher; GRANT SELECT ON CourseMarks TO Teacher; - Chairman
CREATE ROLE Chairman; GRANT SELECT ON CourseMarks TO Chairman;
Question 3
a. Consider the following relational schema for a restaurant database:14
Write a relational algebra for each of the following:
- Retrieve the product names, name of review, and the names of sellers whose products have been reviewed with a rating of 5. 04
- Find the names of users who placed orders for products under the “Households” category, along with the product names and order date.04
- Find the names of seller and the details of the products they are selling at cost more than 100.03
- Display the names of users and their reviews for the products they have rated.04
b. Explain the concepts of left outer join and right outer join through an appropriate example. 06
Ans: Outer Join is an extension of the join operation that avoids loss of information. It computes the join and then adds tuples in the other relation to the result of the join. Uses null to represent missing data. Let us consider two relation:
- course
| course_id | title | dept_name | credits |
|---|---|---|---|
| BIO-301 | Genetics | Biology | 4 |
| CS-190 | Game Design | Comp. Sci. | 4 |
| CS-315 | Robotics | Comp. Sci. | 3 |
- prereq
| course_id | prereq_id |
|---|---|
| BIO-301 | BIO-101 |
| CS-190 | CS-101 |
| CS-347 | CS-101 |
Left Outer Join
course natural left outer join prereq
| course_id | title | dept_name | credits | prereq_id |
|---|---|---|---|---|
| BIO-301 | Genetics | Biology | 4 | BIO-101 |
| CS-190 | Game Design | Comp. Sci. | 4 | CS-101 |
| CS-315 | Robotics | Comp. Sci. | 3 | null |
Here, left outer join took all the values from the left table course and displayed corresponding information of right table prereq. As there is no record of CS-315 in prereq table, it displayed null in prereq_id column.
Right Outer Join
course natural right outer join prereq
| course_id | title | dept_name | credits | prereq_id |
|---|---|---|---|---|
| BIO-301 | Genetics | Biology | 4 | BIO-101 |
| CS-190 | Game Design | Comp. Sci. | 4 | CS-101 |
| CS-347 | null | null | null | CS-101 |
Here, right outer join took all the values from the right table prereq and displayed corresponding information of right table course. As there is no record of CS-347 in course table, it displayed null in title, dept_name & credits column.
Question 4
a. A schedule S, consists of 4 transaction for 5 variables in total. Find the conflicting operation in S and test S for conflicting serializability through precedence graph. If it is serializable, the find the serialized order.10
The order of transaction in S:
Where, means read operation in variable in Transaction .
means write operation in variable in Transaction .
Ans: Table view of Schedule S:
Conflicting operation:
Two operations conflict if they belong to different transactions, access the same data item, and at least one of them is a Write operation. Based on the schedule , the conflicting operations are:
| Data Item | Operation 1 (Preceding) | Operation 2 (Succeeding) | Conflict Direction |
|---|---|---|---|
| A | |||
| B | |||
| B | |||
| B | |||
| B | |||
| B | |||
| D |
Note
Operations on C involve only Reads (), so no conflicts exist for C.
Precedence Graph Construction
Edges:
Tip
Only pick the unique edges from conflict direction.
Graph:
--- config: look: handDrawn --- flowchart LR T1(("T1")) --> T4(("T4")) T2(("T2")) --> T4 & T3(("T3")) T4 --> T3
Since the graph contains no cycles (it is a Directed Acyclic Graph), the schedule is Conflict Serializable.
Serialized Order:
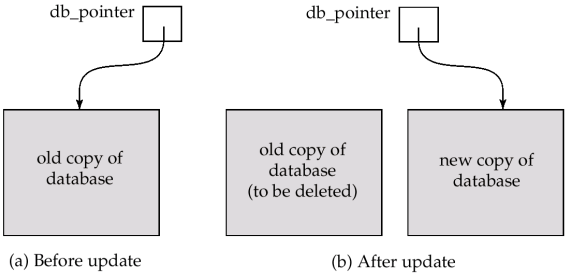
b. How can a shadow-database scheme be implemented to ensure the recoverability of the database?05
Ans: The recovery-management component of a database system implements the support for atomicity and durability.
The shadow-database scheme:
-
Assume that only one transaction is active at a time.
-
A pointer called db_pointer always points to the current consistent copy of the database.
-
All updates are made on a shadow copy of the database, and db_pointer is made to point to the updated shadow copy only after the transaction reaches partial commit and all updated pages have been flushed to disk.
-
In case transaction fails, old consistent copy pointed to by db_pointer can be used, and the shadow copy can be deleted.
c. Illustrate the possible states of a transaction.05
Ans:
--- config: theme: neutral --- graph LR active((Active)) partially((Partially<br/>committed)) committed((Committed)) failed((Failed)) aborted((Aborted)) active --> partially active --> failed partially --> committed partially --> failed failed --> aborted
Question 5
a. Consider the relation-
with the following functional dependency,
If is decomposed into two smaller relations as-
determine the type of this decomposition (lossless or lossy).08
Ans: For a decomposition of relation into sub-relations and to be lossless, the intersection of attributes (the common attributes) must be a superkey for at least one of the sub-relations.
Mathematically, if , then either:
- (A determines all attributes in ) OR
- (A determines all attributes in )
The common attribute between and is:
We must check if the common attribute, patient_name, can uniquely identify the rows in either or based on the given Functional Dependencies ().
The closure of patient_name is just itself:
Since the common attribute () is not a superkey for either of the decomposed relations, the join of these two tables would result in “spurious tuples” (duplicate or incorrect data associations).
Therefore, the decomposition is Lossy.
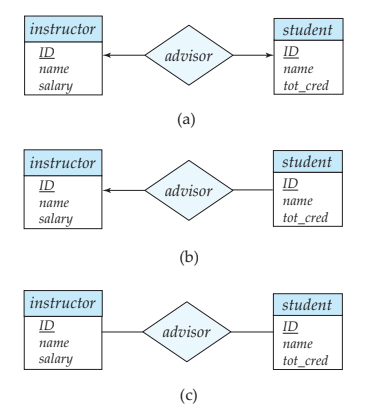
b. Discuss different types of mapping cardinality in the context of an Entity-Relationship (ER) model with examples.06
Ans: There are mainly 4 types if mapping cardinality in a ER model. To distinguish among these types, we draw either a directed line () or an undirected line (— ) between the relationship set and the entity set in question, as follows:
- One-to-one: We draw a directed line from the relationship set advisor to both entity sets instructor and student (see Figure (a)). This indicates that an instructor may advise at most one student, and a student may have at most one advisor.
- One-to-many: We draw a directed line from the relationship set advisor to the entity set instructor and an undirected line to the entity set student (see Figure (b)). This indicates that an instructor may advise many students, but a student may have at most one advisor.
- Many-to-one: We draw an undirected line from the relationship set advisor to the entity set instructor and a directed line to the entity set student. This indicates that an instructor may advise at most one student, but a student may have many advisors.
- Many-to-many: We draw an undirected line from the relationship set advisor to both entity sets instructor and student (see Figure (c)). This indicates that an instructor may advise many students, and a student may have many advisors.
c. What is materialized view? how is it different from non-materialized view?06
Ans: A materialized view is a database object that stores the actual result of a query physically on the disk, much like a standard table. Instead of running the underlying query every time, the database computes the result once (or periodically) and saves it. The fundamental difference lies in when the computation happens and where the data lives.
- Non-Materialized View (Standard View): This is a “virtual” table. It stores only the SQL query definition, not the data. Every time you query a standard view, the database engine executes the underlying query in real-time against the source tables.
- Materialized View: This is a “physical” copy. It executes the query ahead of time and stores the output. When you query it, the database reads the stored output directly, skipping the complex processing (joins, aggregations) required to generate it.
Question 6
a. Write short notes on:10
(i) Canonical cover
(ii) Aggregation
Ans:
b. Explain the ACID properties of database in case of transaction. 06
Ans:
c. Perform the operations in the following B Tree with order = 3.
- Delete K
- Insert C
- Insert I
- Delete J
flowchart TB J(("•J•")) --> DG(("•D•G•")) & LT(("•L•T•")) AB(("A,B")) EF(("E,F")) H(("H")) K(("K")) MO(("M,O")) WX(("W,X")) DG --> AB & EF & H LT --> K & MO & WX
Ans: For order
- Root
- Min child = 2
- Max child = 3
- Internal node
- Min child = 2
- Max child = 3
See B Tree for more details.
Delete K
flowchart TB J(("•J•")) DG(("•D•G•")) MT(("•M•T•")) AB(("A,B")) EF(("E,F")) H(("H")) L(("L")) O(("O")) WX(("W,X")) J --> DG & MT DG --> AB & EF & H MT --> L & O & WX
Insert C
flowchart TB J(("•J•")) CF(("•C•F•")) MT(("•M•T•")) AB(("A,B")) DE(("D,E")) GH(("G,H")) L(("L")) O(("O")) WX(("W,X")) J --> CF & MT CF --> AB & DE & GH MT --> L & O & WX
Insert I
flowchart TB FJ(("•F•J•")) C(("•C•")) H(("•H•")) MT(("•M•T•")) AB(("A,B")) DE(("D,E")) G(("G")) I(("I")) L(("L")) O(("O")) WX(("W,X")) FJ --> C & H & MT C --> AB & DE H --> G & I MT --> L & O & WX
Delete J
flowchart TB FM(("•F•M•")) C(("•C•")) H(("•H•")) T(("•T•")) AB(("A,B")) DE(("D,E")) G(("G")) IL(("I,L")) O(("O")) WX(("W,X")) FM --> C & H & T C --> AB & DE H --> G & IL T --> O & WX
Also, See DBMS Mid Solution. GHILMOTWX